■はじめに
見出しのようなツイートをしたところ珍しく多くの反応があり、当初はtogetterにまとめていたのですが、リプライも追い付かなくなったので、ブログにまとめておきます。
AIを使って著作権ロンダリングすんな、って話をラッダイト運動と一緒にしなさんな。 https://t.co/aTZmbMNmUY
— mohno (@mohno) 2024年10月15日
なお、ここでは画像生成AIについて取り上げるだけで、その他の生成AIについてはほとんど取り上げません。生成AIが使われる分野は、たまたま話題になっている声優(声)やテキスト、音楽、プログラムなどさまざまなものがあり、それぞれ権利の扱われ方は異なるためです。
指摘されたことですし、(一時的に)コミュニティノートも付けられていましたが、「AIを使って著作権ロンダリングすんな」と言ってしまうと「AIを使って著作権ロンダリングできる」と受け取られてしまうおそれがあります。本来、「AIを使って著作権ロンダリングできると誤解すんな」というべきだったかもしれません。
これには背景があります。画像生成AIの“はしり”であるStable Diffusionが取り上げられたとき、生成AIの出力画像に著作権は生じない、と説明されていました。
CC0とは、すっごい簡単にいうと権利放棄で、商用利用OKです。
その後も生成AIは作風や画風を学ぶだけだから学習データの著作権は及ばず侵害にあたらない、という言説を唱えるものも出てきて、生成AIによる出力は無法地帯のようになりました。これは現在も続いています。後述しますが「人力による二次創作が許容されるなら生成AIによる二次創作も許容されるべき」と強弁して侵害にあたる大量の画像を生成する、という例があちことにあります。だからこそ「AIを使って著作権ロンダリングすんな」なのです。もっと直接的な言い方をすれば「盗作すんな」ですけれどね。
■生成AIツールの限界
現在の画像生成AIは権利処理されているはずがないものを学習し、出力することがあります。その点をすがやみつる氏に指摘したところ「改良されて出なくなっています」とおっしゃるので、直接的なプロンプトの入力ははじかれるものの、少し加工するだけでやっぱり出力されました。
※DALL-E3をベースにしていると言われるBing Image Creatorを使いました。
なるほど、改良されているということですね。
— mohno (@mohno) 2024年10月11日
今、Bing Image Creator を使って、こういうのは出せました。https://t.co/IbCaeuXzpmhttps://t.co/rpLl4TuntHhttps://t.co/vpXOrx7Ojk
必ずしも同意を求めませんが、著作権上問題ないデータしか学習していないというのは、私には信じられないですね。 https://t.co/y8khJh9WUG pic.twitter.com/yuGjNxgb5T
なお、「これらはスヌーピーやムーミンやスパイダーマンを学習した結果ではなく偶然の出力であり、どのように利用しても著作権侵害にあたることはない」とお考えの人はこの先を読んでも無駄なのでどうぞお引き取りください。
プロンプトを少し加工しただけで「出そうとして出したんだろ」と言われればその通りですが、問題はそこではありません。ここから分かることは以下の点です。
- 権利処理されるはずがないデータが学習対象になっている
- 学習したデータに明らかな依拠を示す類似性が認められる(排除する仕組みがない)
結果として、「生成AIの出力だから自由に使える」とは思えないような画像が出力されているということです。もし、人としてのイラストレーターに「新しい商品のためにスヌーピーのようなかわいい犬をデザインしてくれ」と依頼して、このようなイラストを納品されたら、そのイラストレーターは二度と仕事がもらえないでしょう。中には不誠実な人がいて盗作を納品することはあるかもしれませんが、それは例外的な話であり、通常は二次的な創作物とは言えない「独自の創作性を持ったイラスト」が納品されるはずです。
現在の生成AIツールは、2.のような出力を排除する機能がないのですから、その出力画像が「独自の創作性を持っている」という保証がありません。学習データは開示されていないので、依拠しているかどうか確認することもできません。もっとも、膨大なデータがただ開示されても、確認できるかどうか分かりませんが。
上記は誰でも知っているような“分かりやすい例”ですが、膨大なデータの中にはあまり知られていないようなクリエイター・イラストレーターの作品もあるでしょう。そうしたものでも著作権は存在します。そして、1.に示した通り当人の許可なく収集され学習の対象になっている可能性が常にあります。故意に有名なキャラクターを出そうとしなければ、それは既存の著作物と依拠性を示すほど類似することはない、と想定できるでしょうか。
本来、生成AIツールの利用者は、出力した画像が既存の著作権を侵害しないという確信は持てないはずです。ところが、ときどき大手がプロモーションで利用したり(他社キャラクターが出力されてオモチャになってたりするみたいですが)、ITの知見をアピールしたい(しかしリテラシーの低い)“大物”クリエイターが使ったりして、まあまあ炎上してます。政府が生成AIの活用に前のめりだったのは赤松健議員のせいではないか、というのも分かります。私は、最初の紹介記事で「ビリー・アイリッシュ」の画像が出ているのを見て「生成した画像が著作権も肖像権も関係なしに再利用できる、とは思えない」と感じましたけどね。
学習データをどこから入手しているのか知らないが、"portrait of billie eilish"あたりを見る限り、生成した画像が著作権も肖像権も関係なしに再利用できる、とは思えない。“技術的”に生成している以上、創作性もないよね。 / “やばすぎるAI画像生成サービス「Stable Diffu…” https://t.co/7j4fnVd3Ck
— mohno (@mohno) 2022年8月22日
■訴訟しろという圧力
複数の人から「侵害してるというなら裁判すればいいだけ。裁判に訴える気がないなら、問題ないということ」という反応がありました。それぞれの方のご意見としては承りますが、同意はできません。実際に裁判に訴えている人もいるようですが、そもそも日本には懲罰的賠償金という制度がないので、民事裁判では訴訟費用負けしてしまう可能性が高いのが実情です。また、「裁判で負けるのでないなら問題ない」という前提を想定するなら、SNSでの誹謗中傷や世の中のイジメ問題など社会で生じている多くの問題が「裁判沙汰になっていないのだから問題ない」と片付けられてしまうことになります。ジャニーズ事務所の性加害問題なんて何も問題なんてなかった、となるわけですが、その考え方は倫理的に問題ないのでしょうか。
かつて、日本には「不正にアップロードされたコンテンツをダウンロードするのは合法」という時代がありました。アメリカの弁護士が「どうしてそれが合法なんだ!」と驚いていましたが、それは倫理的ではなく目に余る状態になったので違法扱いされるようになりました。話題になっている声優の生成AIによる無断利用がどこまで現行法で取り締まることができることができるのか分かりませんが、このような使われ方が倫理的であるはずがなく、乱用が続くなら法整備なり事業者の運用方法を変えるなどして対応すべき、というのはごく普通の考え方でしょう。画像系の生成AIについても同じです。
ここまで説明しても「裁判に訴える気がないなら、問題ないということ」という考えの人は、個人のご意見として承りますが、私は同意しません。
■日本の特殊性とコミケ(同人誌)
ところで、日本で大きな問題になっているのは「偶然、既存の作品に類似してしまうこと」よりも「明確に特定の作家や作品が狙われていること」だと考えています。Yahoo!オークションなどでアニメのキャラクターを検索してみると、生成AIが使われたと思われるグッズが大量に出てきます。
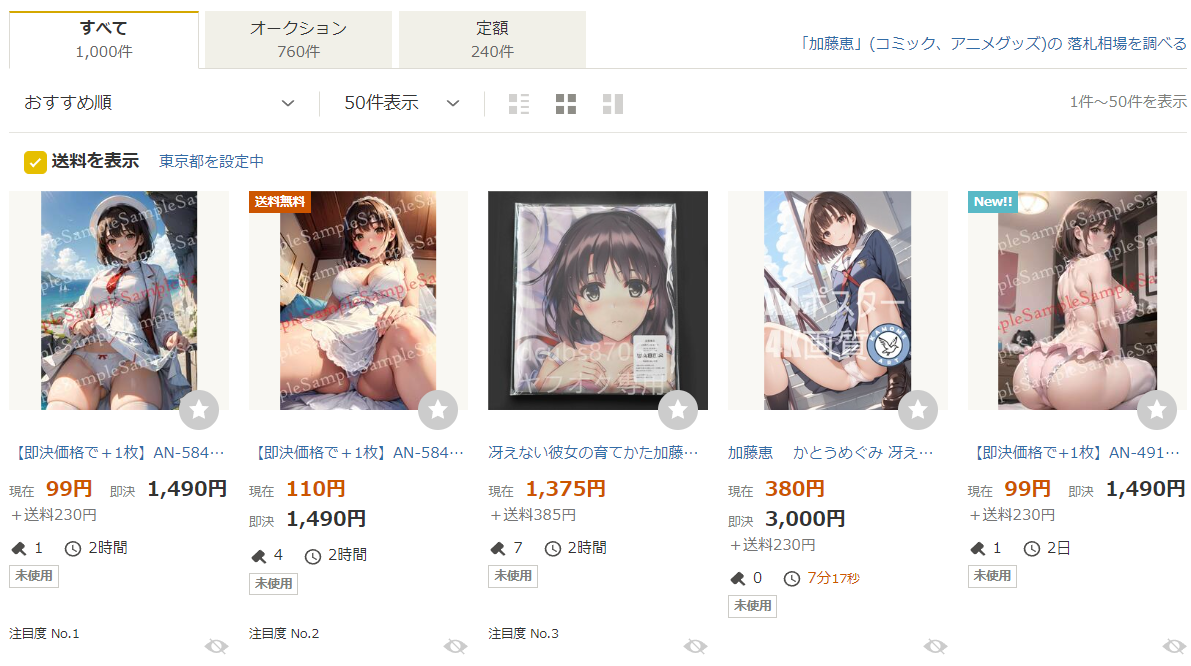

報道を見ている限り、欧米での生成AIの問題は児童ポルノやフェイク目的で使われることで、このような使われ方が問題視されているようには見えません。そもそも、このような使われ方を見かけません。そりゃそうでしょう。スヌーピーやディズニー、マーベルのキャラクターで同様のことをしたら見過ごされることなく、即座に訴えられるでしょう。もし、「そんなことはない! 欧米の方が著作権は緩い!」と考えている人がいたら、ぜひ試してほしいと思います。
実のところ、日本ほど二次創作に甘い国はありません。ごく一部の例外を除いて、同人活動という名目で商用作品を模したマンガやイラストなどが許容されてきました。アメリカの著名な弁護士が日本のコミケについて「すばらしい活動。しかし、同じことをアメリカでやったら即座に潰されるだろう」と言っていたくらいです。長くコミケを運営していた故・米沢嘉博氏は多くのクリエイターから尊敬され、評価されています。日本は著作権が法律上も運用も緩い国で、私的な複製を明文で許容したり、レンタルCD(レコード)という業態が認められているくらいです。商業ではない二次創作、という名目で大量の同人誌が売られているのも日本の著作権運用が緩いからです。一部のアジテーターが煽るせいで誤解している人も見かけますが、日本こそが「著作権が緩いおかげでコンテンツビジネスが盛り上がっている類稀な国」なのです。
そして、生成AIを使った上記のような例は、この「日本の著作権運用の緩さ」の悪用です。人が画力アップのために既存の作品をマネたり、それを同人誌として売ることは、多くのクリエイターが通った道であり、お互い様として容認されてきましたが、それを悪用して生成AIでも「同人活動」と言って活動しているのです。言うまでもありませんが、“二次創作”というなら元の著作者の意向に反して利用することはできません。人がスキルアップするなら許容できることでも、機械的な模造作品が大量生産されることを許容できないというのは普通の感覚でしょう。プロフィールに「学習禁止」「生成AI禁止」のように明記しているクリエイターはたくさんいます。こんなことも言われなきゃ分からないのですかね。ダメに決まってるだろ。
■規制のあり方
前述しましたが、欧米における生成AIの問題は児童ポルノやフェイク目的であり、生成AIに対する規制もそれらを想定したものになっています(記事1、記事2)。もともと日本政府は著作権法を緩めに解釈しようとしますし、グーグルブック検索では集団訴訟したアメリカや国レベルで動きのあったドイツ・フランスと違って、まったくの放置でした。そうした上で、生成AIを有効利用させるためにどのような規制ができるでしょうか。
まずやってもらいたいのは「AI出力」の明記化です。私自身はクリエイターでもなんでもない、ただのユーザーですが、上記のように検索で生成AIが見つかってくるのは“邪魔”以外の何物でもありません。生成AIを使ったら、その旨の表示を義務付ければ、検索時にフィルタリングできるようになります。それくらいは必須としてほしいものです。また、生成AIは上記のような侵害リスクを抱えているわけですから、特定商取引法に基づく表記のように使用者の情報公開が義務付けられればなお良いです。
次に、学習データの開示もしてほしいところです(当然、検索しやすい形で)。本当に裁判を起こすなら、学習データとして依拠しているかどうかを調べるのが簡単です。スヌーピーなどを例示したとおり、学習しているから出力された、ということが裁判を起こす前に確認できるようになります。オプトアウトできればなお良いです。
■訴訟費用の負担
本題ではないですが、OpenAIはChatGPT Enterprise顧客に限り、著作権侵害で訴えられた場合の裁判費用を負担することを発表しています(Copyright Shield)(記事3、OpenAIの発表)。
サービス規定(1. APIサービスについて)を読むと、あらかじめ侵害が分かっている場合には適用されないようなので、上記のような著名なキャラクターについては、プロンプトを工夫して出力させたところで適用されないでしょう。あくまで「盗作になるとは知らずに使っていた(それほど著名でない)作品」に対して請求される金額が補償されるということなのだと思います。一方、その場合でも「永続的に使えるようにしてくれる」とは読み取れませんでした。当然のことですが、著作権は「いくら金を積まれても使わせない」という判断ができるものなので、彼らの生成AIを使った画像を商品化していた場合に侵害が発覚したら差し止めをくらうくらいはあるように思います。侵害が発覚した後の利用まで補償される気はしません。
生成AIでなくても「素材サイトに盗作が登録されていて、差し止めることになった」という事例はありますが、類似性を排除するフィルター機能がない以上、侵害のおそれがある出力はある程度の確率で生じるものであり、盗作のような悪意が入るこむことによるトラブルと同一視するのは難しいと思います。(ここに同意しない人がいるであろうことは予想します)
■イラストのラッダイト運動
さらに余談ですが、イラスト系のラッダイト運動と言えそうなものはあります。「いらすとや」(の排除)です。「いらすとや」は、素材という需要に着目し、精力的なイラストの制作と無料から(あるいは安価で)使えるという利便性で、広く活用されています。一方で「イラストレーターの仕事を奪っている」という話もありました(togetterのまとめ1、まとめ2)。「いらすとやを禁止しろ」という強いメッセージを見たわけではないですが、そのようなことがあれば、そういうものは「ラッダイト運動」とみなしてよいと思います。現在、画像系の生成AIに起きていることは、そのレベルではない、ということです。